| How to use ansible with S3 | 您所在的位置:网站首页 › Uploading objects › How to use ansible with S3 |
How to use ansible with S3
|
0
S3 has become the cheap and best object storage and it is used widely across enterprises and products, to securely save and access data over the internet. We have various ways to interact with the S3 bucket,聽 to upload, download and copy objects back and forth to S3. SDKs ( Boto, AWS SDK for Javascript etc) AWS CLI AWS ConsoleWe have written an article on how to use AWS CLI with S3 How can we talk about infrastructure efficiency and cloud automation without Ansible? So, In this article, we are going to see how to use Ansible for managing objects in the S3 bucket We are going to see how to use Ansible to upload files to S3, Download files from S3 and copy files to S3 etc. With no further ado. lets go-ahead
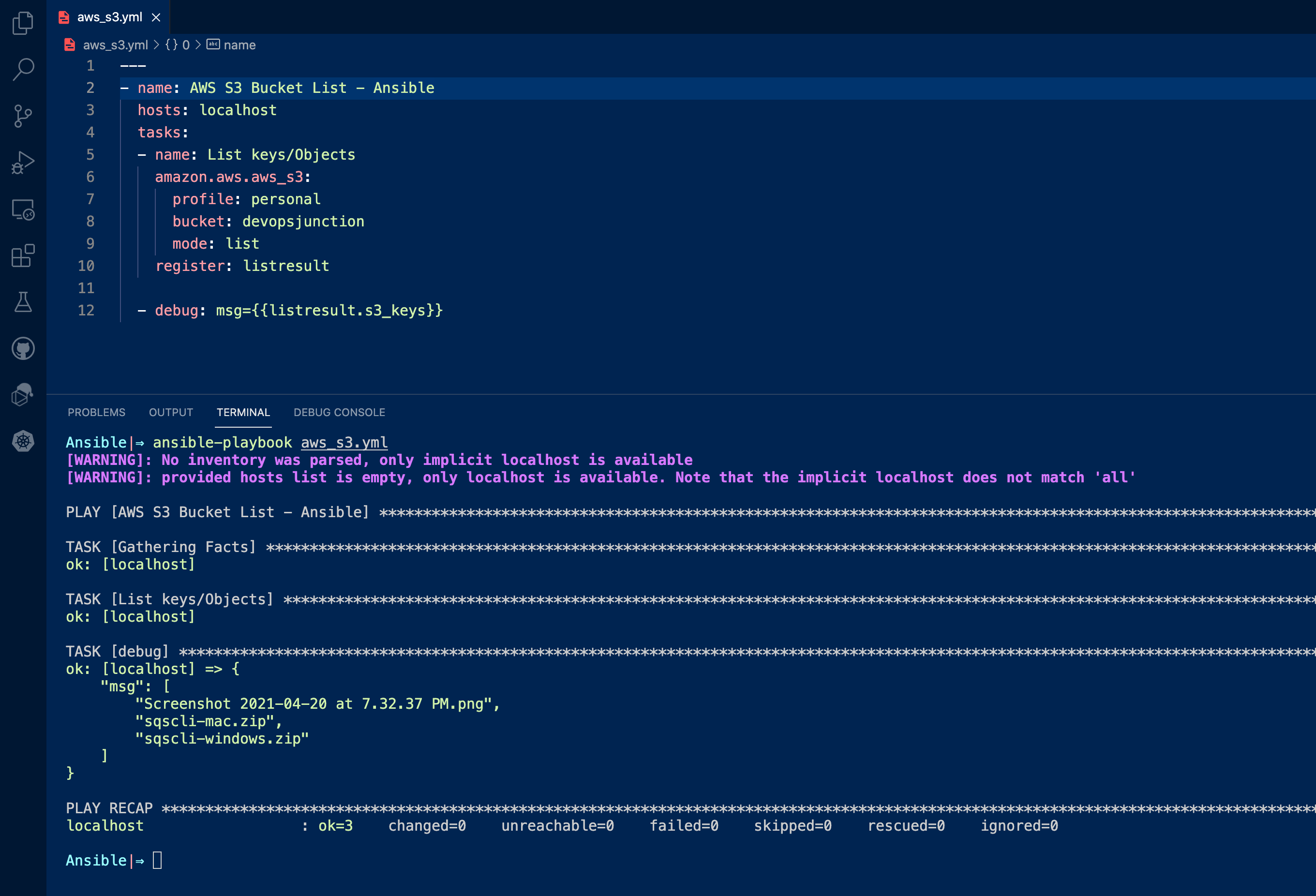
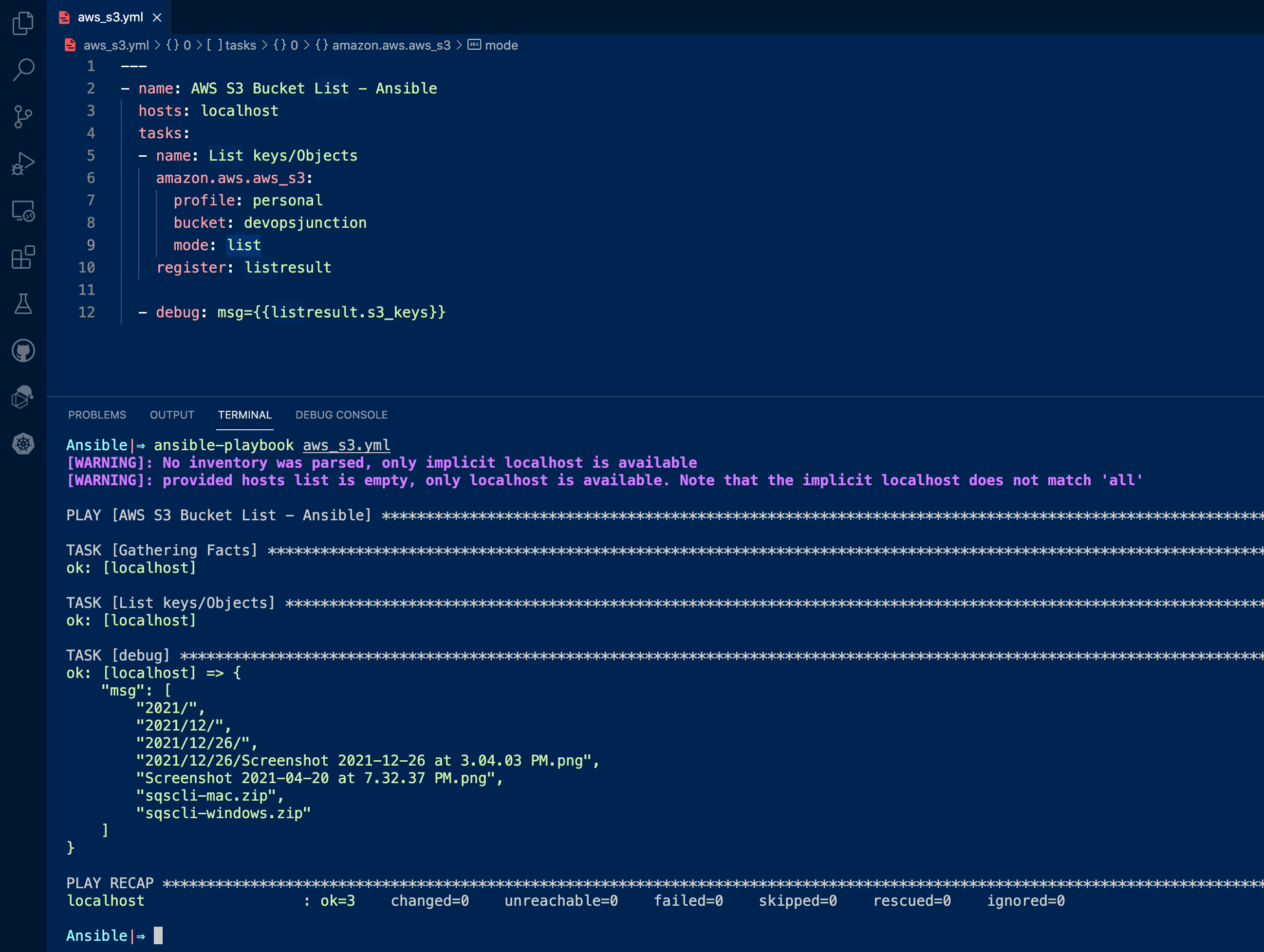
Table of Contents Things to know before moving on We presume you have AWS CLI configured or have AWS ACCESS KEY/SECRET PUT and Upload are the same GET and Download are the sameThere are various modes of operation available with Ansible S3. PUT: upload GET: download geturl: return download URL getstr: download object as a string list: list keys / objects create: create bucket delete: delete bucket delobj: delete object copy: copy object that is already stored in another bucketFor the aws_s3 module to work you need to have certain package version requirements The below requirements are needed on the host that executes this module. python >= 3.6 boto3 >= 1.15.0 botocore >= 1.18.0you can check your these things using the following commands ansible – version that shows the python interpreter version and ansible version pip list|grep boto or pip3 list|grep boto shows the boot3 and botocore versionAnsible S3 List Examples Ansible S3 List Objects in a Bucket In S3 parlance the name of the object is known as a key.聽 It is kept that way to align with the Object storage principle of S3. As you know Objects are created with Keys and values. Every object you store are referred to with their name also known as key Here is the Ansible Playbook that lists bucket devopsjunction using mode: list Since I have multiple named profiles in AWS CLI. I need to instruct Ansible to use the right profile by mentioning profile: personal If no profile is specified, Ansible would choose the default AWS CLI profile --- - name: AWS S3 Bucket List - Ansible hosts: localhost tasks: - name: List keys or Objects amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: list register: listresult - debug: msg={{listresult.s3_keys}}here is the execution output of this playbook
This is how you can list the objects in the bucket. Will it list the directories and subdirectories? Yes, By default, the list mode of Ansible would list the objects and their subdirectories if they are a directory. You can limit the number of keys/objects to be returned using a value called max_keys which we will see later. Here is the output of the same playbook listing the directories and their content
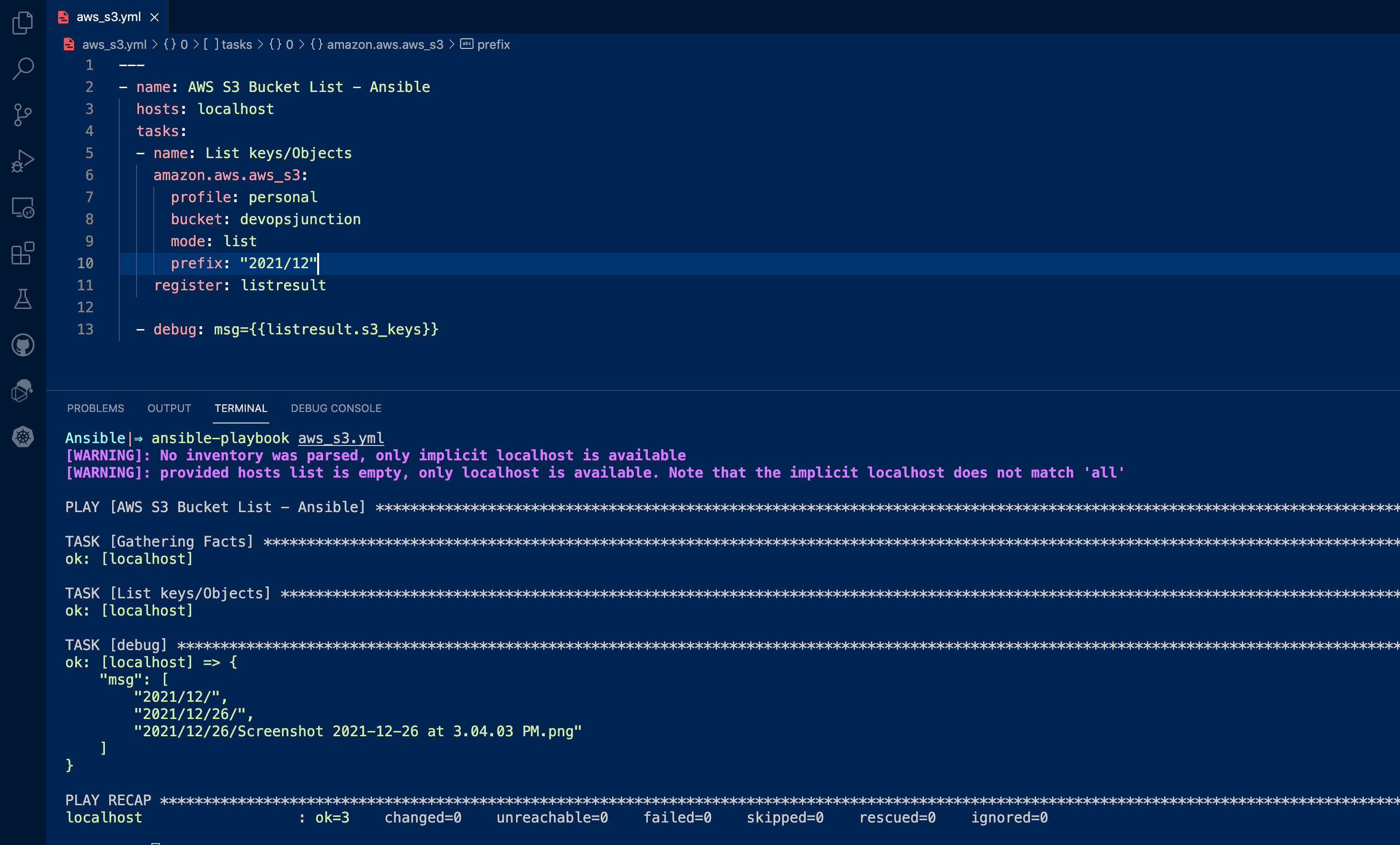
Ansible S3 List Objects using the prefix Now let us suppose we have so many files in our S3 buckets and categorized into directories and subdirectories like this Let's say we are maintaining a directory for every single month for each year like this. What If we want to list only the files of聽 2021 and 12th month Based on the directory convention we follow, we can use 2021/12 as the prefix to display all the files of Dec 2021.
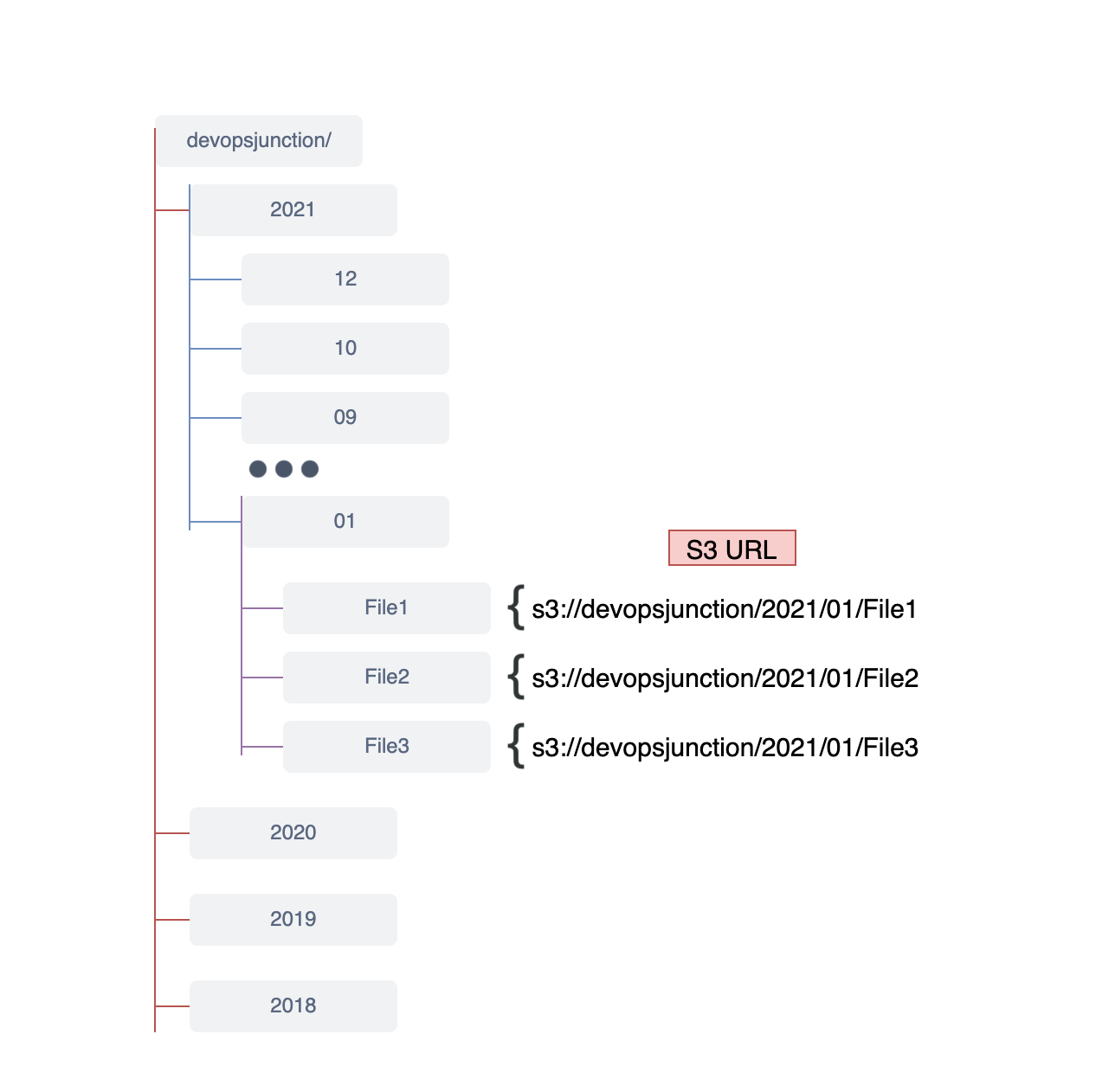
Here is the Playbook with the prefix --- - name: AWS S3 Bucket List - Ansible hosts: localhost tasks: - name: List keys/Objects amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: list prefix: "2021/12" register: listresult - debug: msg={{listresult.s3_keys}}
Here is the execution output of this playbook. you can see only the files matching the prefix are listed. It is more like using a wildcard as a prefix in ls -lrt command if you are familiar with linux
Control the No of objects returned with max_keys As time goes on S3 objects and their subdirectories and files would become more complex and grow. Just imagine having a Million files and subdirectories under each directory. When you execute a list command on the bucket with millions and billions of objects. you need to set a limit on how many objects you can get as a result. By default this value is 1000聽 but not all the time we want 1000, right? so to limit it we can use the max_keys property with some numeric value Here is the playbook with the max_keys set to 400.聽 It would restrict the number of returned objects to 400 despite there are more than 400 --- - name: AWS S3 Bucket List - Ansible hosts: localhost tasks: - name: List keys/Objects amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: list prefix: "2021/12" max_keys: 400 register: listresult - debug: msg={{listresult.s3_keys}}
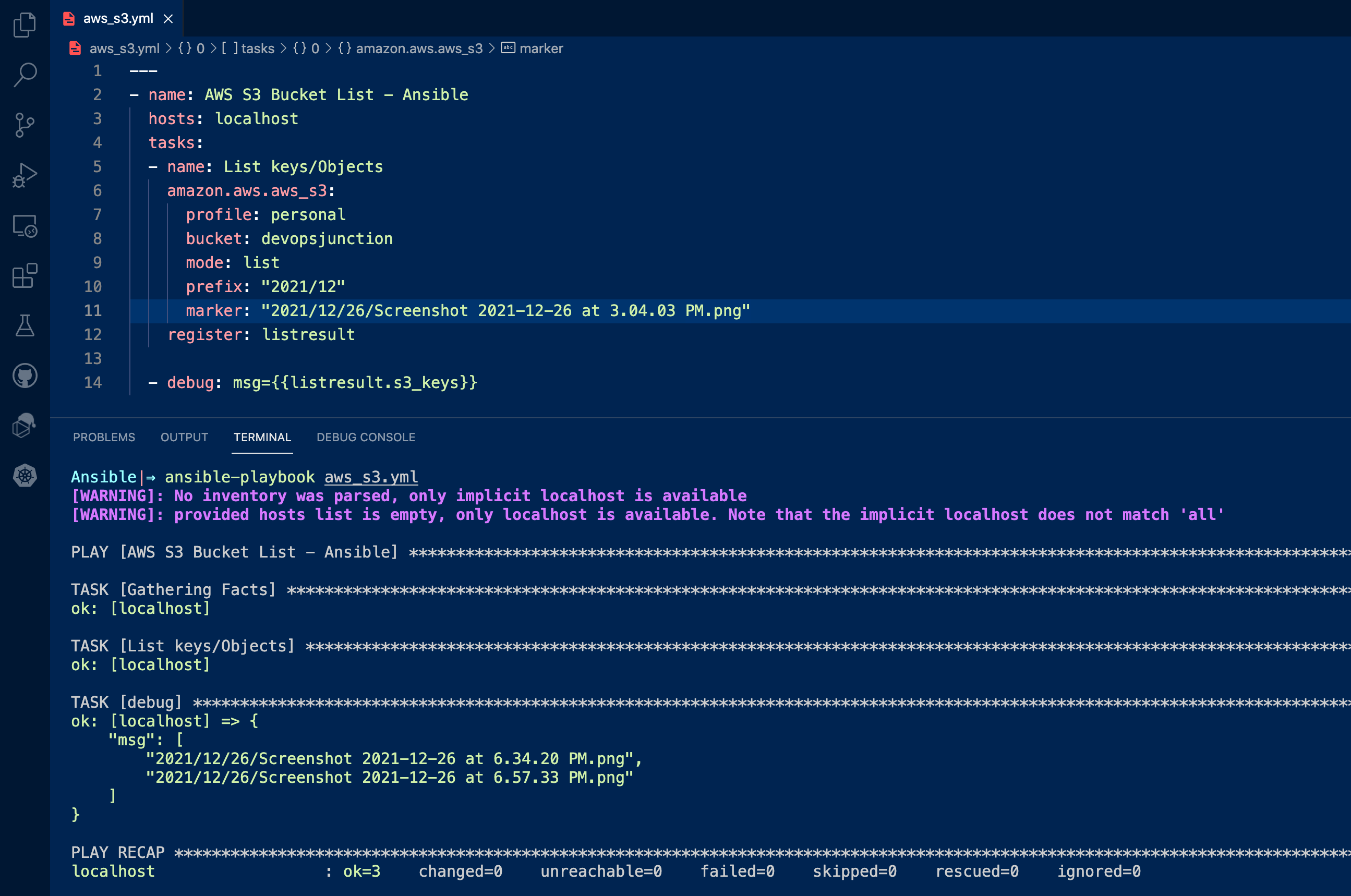
Specify where to start when listing objects with a marker when you are listing objects, the objects are returned in ascending order based on their name. For example, consider this resultset. ok: [localhost] => { "msg": [ "2021/12/", "2021/12/26/", "2021/12/26/Screenshot 2021-12-26 at 2.43.55 PM.png", "2021/12/26/Screenshot 2021-12-26 at 2.58.51 PM.png", "2021/12/26/Screenshot 2021-12-26 at 3.04.03 PM.png", "2021/12/26/Screenshot 2021-12-26 at 6.34.20 PM.png", "2021/12/26/Screenshot 2021-12-26 at 6.57.33 PM.png" ] }Now I want to list only the objects starting from the third one 2021/12/26/Screenshot 2021-12-26 at 3.04.03 PM.pngThat's where the marker parameter comes into the picture. Here is the playbook with marker --- - name: AWS S3 Bucket List - Ansible hosts: localhost tasks: - name: List keys/Objects amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: list prefix: "2021/12" marker: "2021/12/26/Screenshot 2021-12-26 at 3.04.03 PM.png" register: listresult - debug: msg={{listresult.s3_keys}}
Here is the result of this playbook
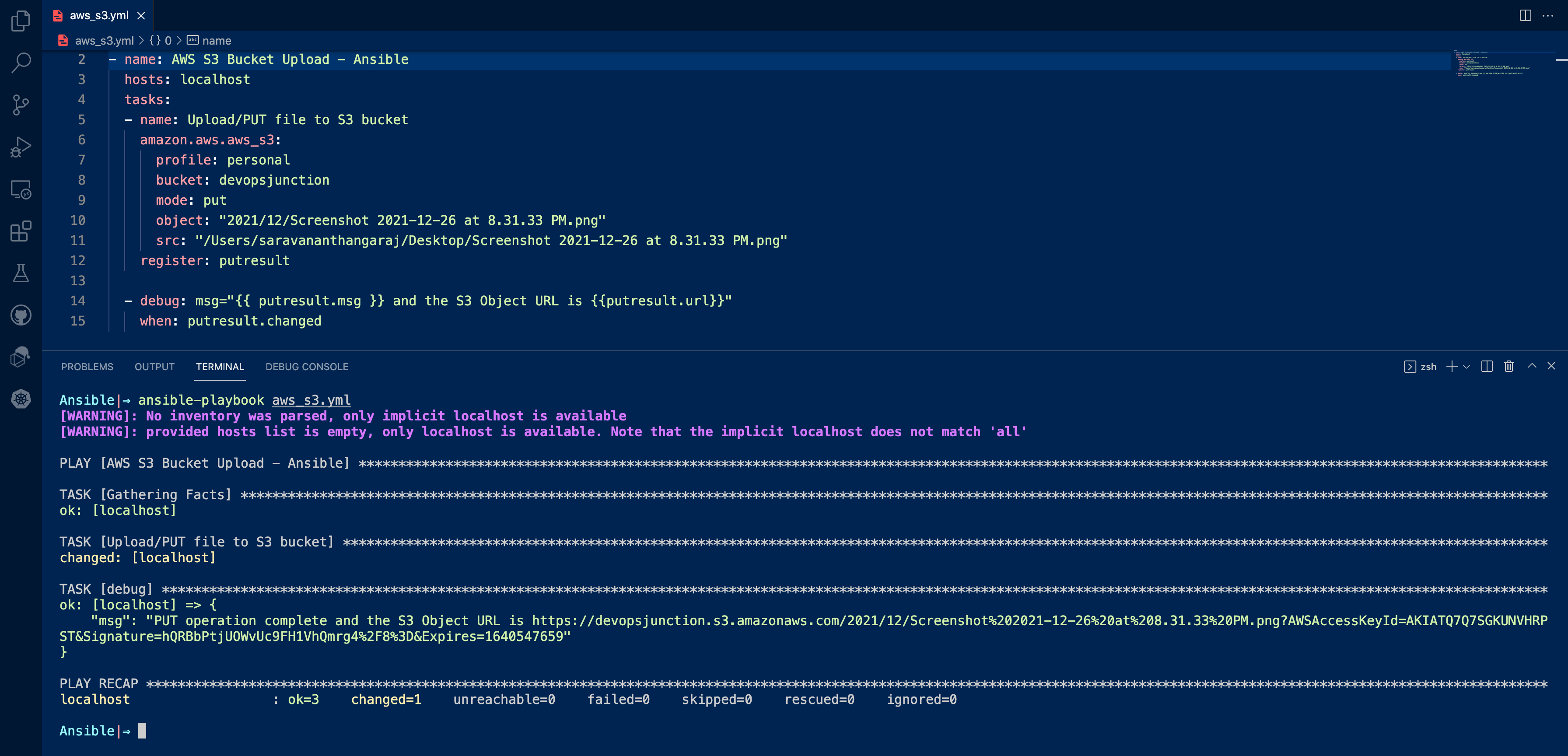
Ansible S3 Upload Examples Before we proceed to. upload files to S3 there are some key points we need to be aware of. An Amazon S3 bucket has no directory hierarchy such as you would find in a typical computer file system. You can, however, create a logical hierarchy by using object key names that imply a folder structure. For example, instead of naming an object聽sample.jpg, you can name it聽photos/2006/February/sample.jpg. This would create the necessary directory structure if it is not already present. If it present, It would upload your file there. Ansible S3 Upload / PUT example Uploading a file to S3 is technically known as PUT and we need to execute a PUT call to upload a file to S3. Now let us see how to use Ansible to upload a file using the PUT mode. --- - name: AWS S3 Bucket Upload - Ansible hosts: localhost tasks: - name: Upload/PUT file to S3 bucket amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: put object: "2021/12/Screenshot 2021-12-26 at 8.31.33 PM.png" src: "/Users/saravananthangaraj/Desktop/Screenshot 2021-12-26 at 8.31.33 PM.png" register: putresult - debug: msg="{{ putresult.msg }} and the S3 Object URL is {{putresult.url}}" when: putresult.changedwhen you are uploading a file that is not present, it would be created. If it is already present and if the bucket versioning is enabled, the old version of the file would be replaced with this new file you are uploading. you can optionally retrieve the old versions in case if you need them. If the file is already present but the Versioning is not enabled, you would end up overwriting the data forever.聽 Even if you have accidentally done it. So Enabling Bucket versioning is highly recommended if you are storing critical data and do not want to end up losing it. Enabling Bucket Versioning would also enforce MFA for delete actions so the files or the versions cannot be deleted easily.
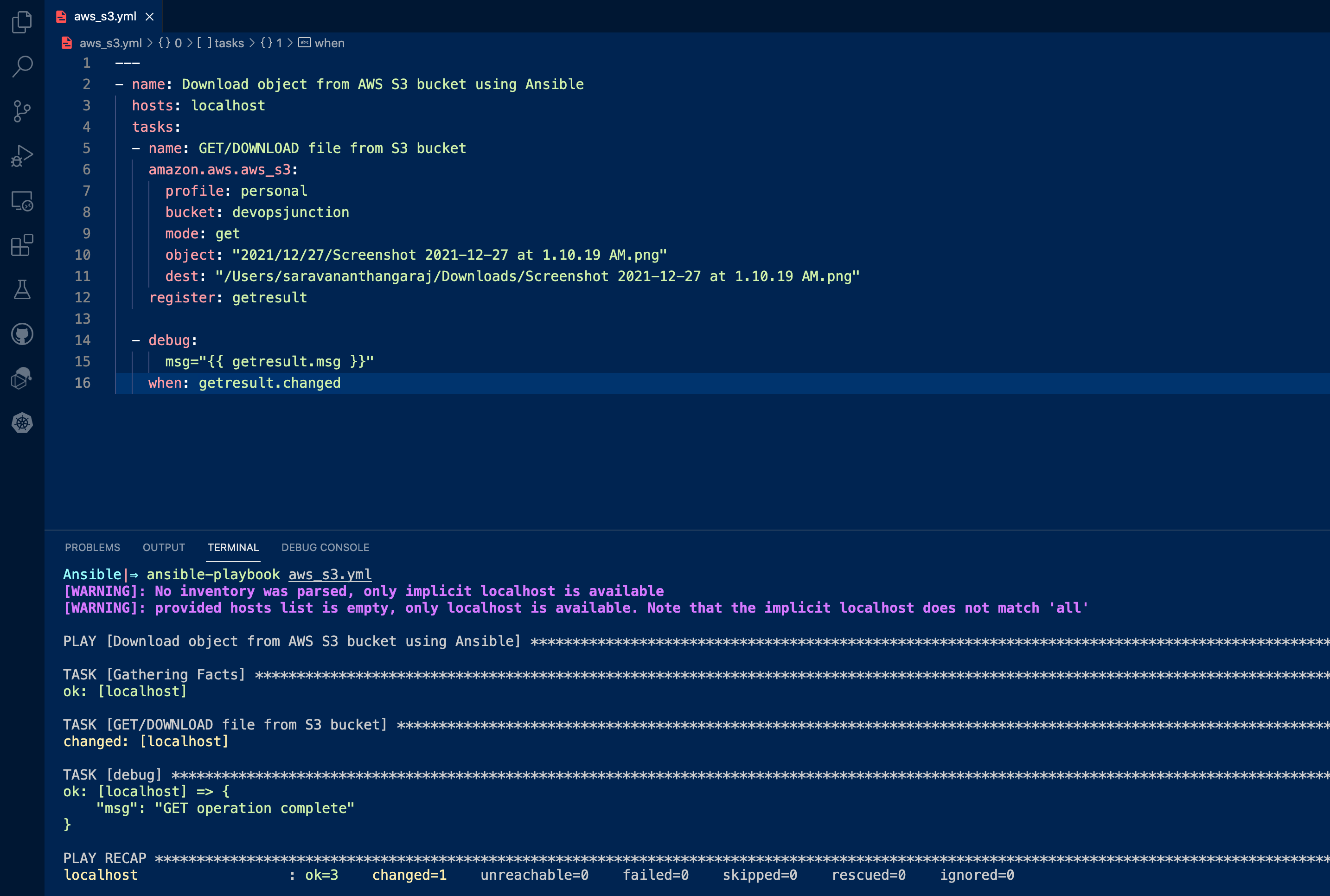
Ansible S3 PUT / UPLOAD rendered template - Dynamic Content At times we might want to generate a file with dynamic content using the Ansible Jinja2 template and then upload it to the S3 bucket. How can we do that? Well, let's see a quick example. I am going to list my Desktop directory with ls -lrt command and save the results into a file and upload that file into S3. Here is the playbook and it does the following things Execute the command and store the result into register variable Using set_fact create a new fact variable and store the collected directory listing,聽 the data type would be a list of files Display the fact variable we have created using debug Using template and Jinja2, Iterate over the list of files and write into a file using lookup Redirect the lookup output to the content stream of aws_s3 and create a new file and upload to S3 --- - name: AWS S3 Bucket Upload - Ansible hosts: localhost tasks: - name: List Desktop and save the output to register variable shell: "ls -lrt /Users/saravananthangaraj/Desktop" register: dirlist - name: Save the output to Content varible set_fact: content: "{{dirlist.stdout_lines}}" when: dirlist.changed - name: Display the Content before Writing debug: msg="{{content}}" - name: Upload/PUT file to S3 bucket amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: put object: "2021/12/27/DesktopDirectoryListing.txt" content: "{{ lookup('template', 'directorylist.yml.j2')}}" register: putresulthere is the template file we are using in the lookup {% for line in content %} {{line}} {% endfor %}both these files are kept in the same directory so I am referring to just the file name with lookup and template. So the content would be placed into this file and then copied over to the S3 with the name DesktopDirectoryListing.txt If you go to S3 and download the file and view it, you can see the directory listing. Ansible S3 PUT / UPLOAD with Custom Headers & Metadata S3 lets you control the access and versioning of the objects by specifying custom headers and metadata For example, you want to give permission to a user X for the object you are uploading right now, based on the email address of his AWS account. you can do that with the following headers x-amz-grant-full-control: GrantFullControl x-amz-grant-read: GrantReadIn fact, there are more Headers available for you to use while uploading the objects. Here is the list of headers taken from AWS Documentation PUT /Key+ HTTP/1.1 Host: Bucket.s3.amazonaws.com x-amz-acl: ACL Cache-Control: CacheControl Content-Disposition: ContentDisposition Content-Encoding: ContentEncoding Content-Language: ContentLanguage Content-Length: ContentLength Content-MD5: ContentMD5 Content-Type: ContentType Expires: Expires x-amz-grant-full-control: GrantFullControl x-amz-grant-read: GrantRead x-amz-grant-read-acp: GrantReadACP x-amz-grant-write-acp: GrantWriteACP x-amz-server-side-encryption: ServerSideEncryption x-amz-storage-class: StorageClass x-amz-website-redirect-location: WebsiteRedirectLocation x-amz-server-side-encryption-customer-algorithm: SSECustomerAlgorithm x-amz-server-side-encryption-customer-key: SSECustomerKey x-amz-server-side-encryption-customer-key-MD5: SSECustomerKeyMD5 x-amz-server-side-encryption-aws-kms-key-id: SSEKMSKeyId x-amz-server-side-encryption-context: SSEKMSEncryptionContext x-amz-server-side-encryption-bucket-key-enabled: BucketKeyEnabled x-amz-request-payer: RequestPayer x-amz-tagging: Tagging x-amz-object-lock-mode: ObjectLockMode x-amz-object-lock-retain-until-date: ObjectLockRetainUntilDate x-amz-object-lock-legal-hold: ObjectLockLegalHoldStatus x-amz-expected-bucket-owner: ExpectedBucketOwner BodyYou can read more about them here PUT Object headers Object metadataHere is the Ansible Playbook --- - name: AWS S3 Bucket Upload - Ansible with Metadata and headers hosts: localhost tasks: - name: Upload/PUT file to S3 bucket amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: put object: "2021/12/27/Screenshot 2021-12-27 at 1.10.19 AM.png" src: "/Users/saravananthangaraj/Desktop/Screenshot 2021-12-27 at 1.10.19 AM.png" headers: '[email protected]' metadata: 'Content-Encoding=gzip,Cache-Control=no-cache' register: putresult - debug: msg="{{ putresult.msg }} and the S3 Object URL is {{putresult.url}}" when: putresult.changedAnsible S3 Download / GET Examples In this section, we are going to see a few examples of how to use Ansible to download objects from S3. Ansible S3 GET / Download Object聽 - Single File To download or GET the object from the S3 bucket we are using the get mode of ansible aws_s3 module Here is the example playbook that downloads a single file from S3 to local --- - name: Download object from AWS S3 bucket using Ansible hosts: localhost tasks: - name: GET/DOWNLOAD file from S3 bucket amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: get object: "2021/12/27/Screenshot 2021-12-27 at 1.10.19 AM.png" dest: "/Users/saravananthangaraj/Downloads/Screenshot 2021-12-27 at 1.10.19 AM.png" register: getresult - debug: msg="{{ getresult.msg }}" when: getresult.changedThe result of this playbook would be like this
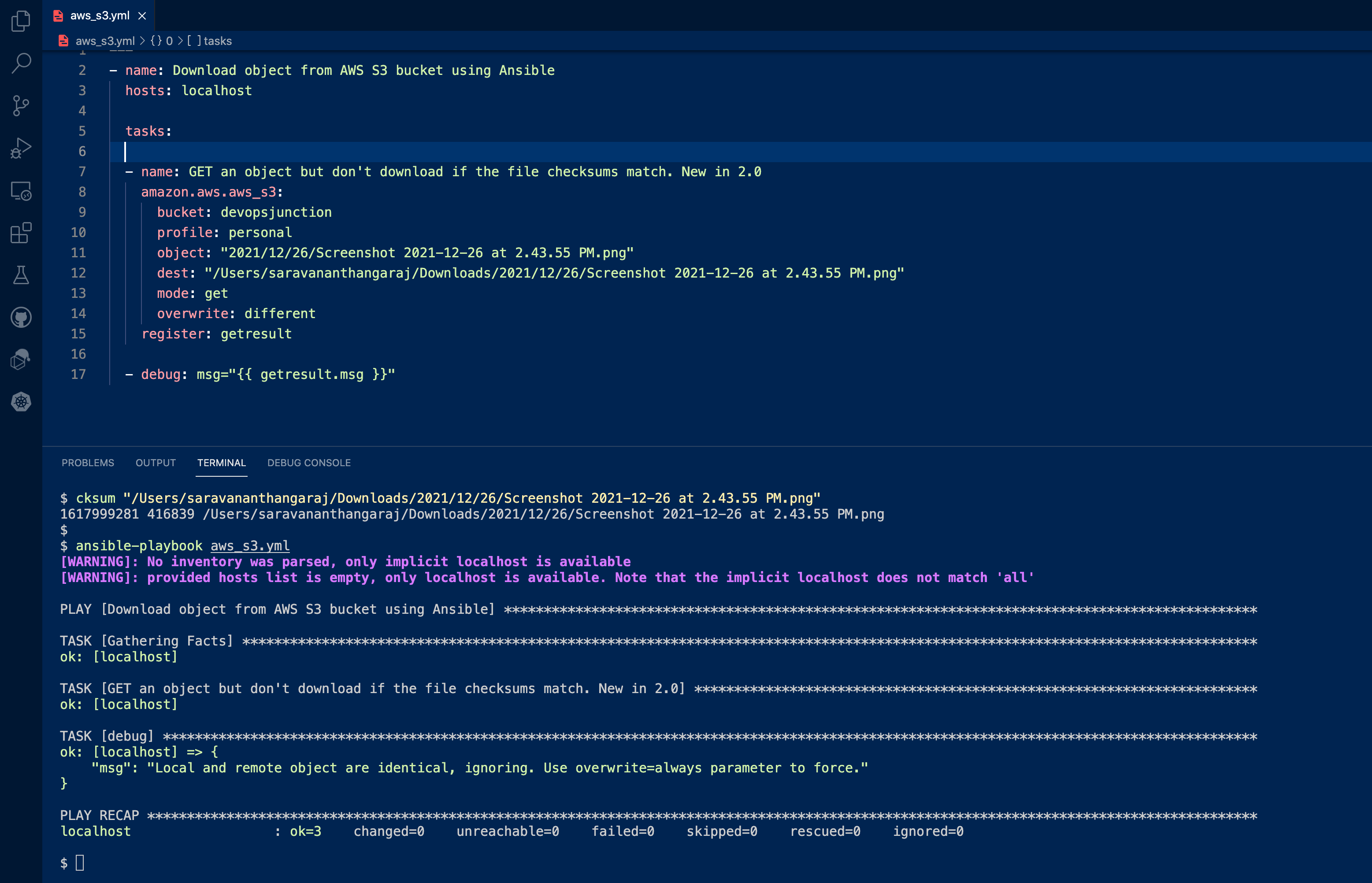
Ansible S3 GET / Download Object聽 - How to download Directory recursively To download a directory with its content from S3.聽 There is no available option in the S3 console as you may know the only option we have is recursive option in AWS CLI S3 as we have covered in our other article But in Ansible there is no such recursive option as we have checked. so we created a workaround the obvious way Get a list of Directories and Files and save it in a list and try to download one by one by iterating over the directories and files We are using some Advanced Ansible concepts like map filter and Jinja2 expressions in this. If you are new to these items please refer our other exclusive articles on those topics Ansible Map Introduction and Examples Jinja3 Designer DocumentationHere is the playbook --- - name: Download object from AWS S3 bucket using Ansible hosts: localhost vars: - directories: [] - files: [] - destlocation: "/Users/saravananthangaraj/Downloads" tasks: - name: Get the list of files first amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: list prefix: "2021/12/" register: listresult - name: Get the list of Directories set_fact: directories: '{%if item is not none %}{{ directories }} + [ "{{ item }}" ] {% else %}{{directories}}{% endif %}' with_items: "{{ listresult.s3_keys | map('regex_search', '^.+\/$') }}" - name: Get the list of Files set_fact: files: '{%if item is not none %}{{ files }} + [ "{{ item }}" ] {% else %}{{files}}{% endif %}' with_items: "{{ listresult.s3_keys | map('regex_search', '^.+[^\/]$') }}" - name: Create the directories first shell: | mkdir -p {{item}} args: chdir: "{{destlocation}}" with_items: "{{directories}}" - name: GET/DOWNLOAD file from S3 bucket amazon.aws.aws_s3: profile: personal bucket: devopsjunction mode: get object: "{{item}}" dest: "{{destlocation}}/{{item}}" register: getresult with_items: "{{files}}" - debug: msg="{{ getresult.msg }}" when: getresult.changedI guess it would be better to explain this over the video. here you go. Hope the video clarifies if you have any doubt, with that let's move to another example Ansible S3 GET / Download Specific version of Object If your S3 bucket is production standard then you might be having Bucket Versioning enabled. When the bucket versioning is enabled. When you upload an object which is already present in S3. it would not be completely overwritten rather replaced with the latest and the old version can still be accessed You can list the available versions of each object in S3 management console on the versions tab If you know the version ID you can pass it while trying to download the object using the version parameter - name: Get a specific version of an object. amazon.aws.aws_s3: bucket: devopsjunction object: 2021/12/26/Screenshot 2021-12-26 at 2.43.55 PM.png version: 48c9ee5131af7a716edc22df9772aa6f dest: /home/sarav/Downloads/Screenshot 2021-12-26 at 2.43.55 PM.png mode: getAnsible S3 GET / Download Only when the Checksum does not match There is a parameter in the s3 module named overwrite which adds control over the overwriting behaviour of the Upload(PUT) or download( GET) tasks By default, it is set to always overwrite if the object exists either upload/download. Besides always overwrite accepts two more values never聽 - Do not overwrite different - Overwrite when the checksum is differentIf you do not want to overwrite either while uploading or downloading. you can set this parameter to never the different value is to validate the checksum of the objects before performing the action. If the Checksum is different, then perform the action. Can either be upload or download Here is the playbook that downloads the object from S3 when checksums are different --- - name: Download object from AWS S3 bucket using Ansible hosts: localhost tasks: - name: GET an object but don't download if the file checksums match. New in 2.0 amazon.aws.aws_s3: bucket: devopsjunction profile: personal object: "2021/12/26/Screenshot 2021-12-26 at 2.43.55 PM.png" dest: "/Users/saravananthangaraj/Downloads/2021/12/26/Screenshot 2021-12-26 at 2.43.55 PM.png" mode: get overwrite: different register: getresult - debug: msg="{{ getresult.msg }}"
If the checksums are matching you would see a message like this and the task would be OKand not CHANGED Local and remote object are identical, ignoring. Use overwrite=always parameter to force.Here is the output
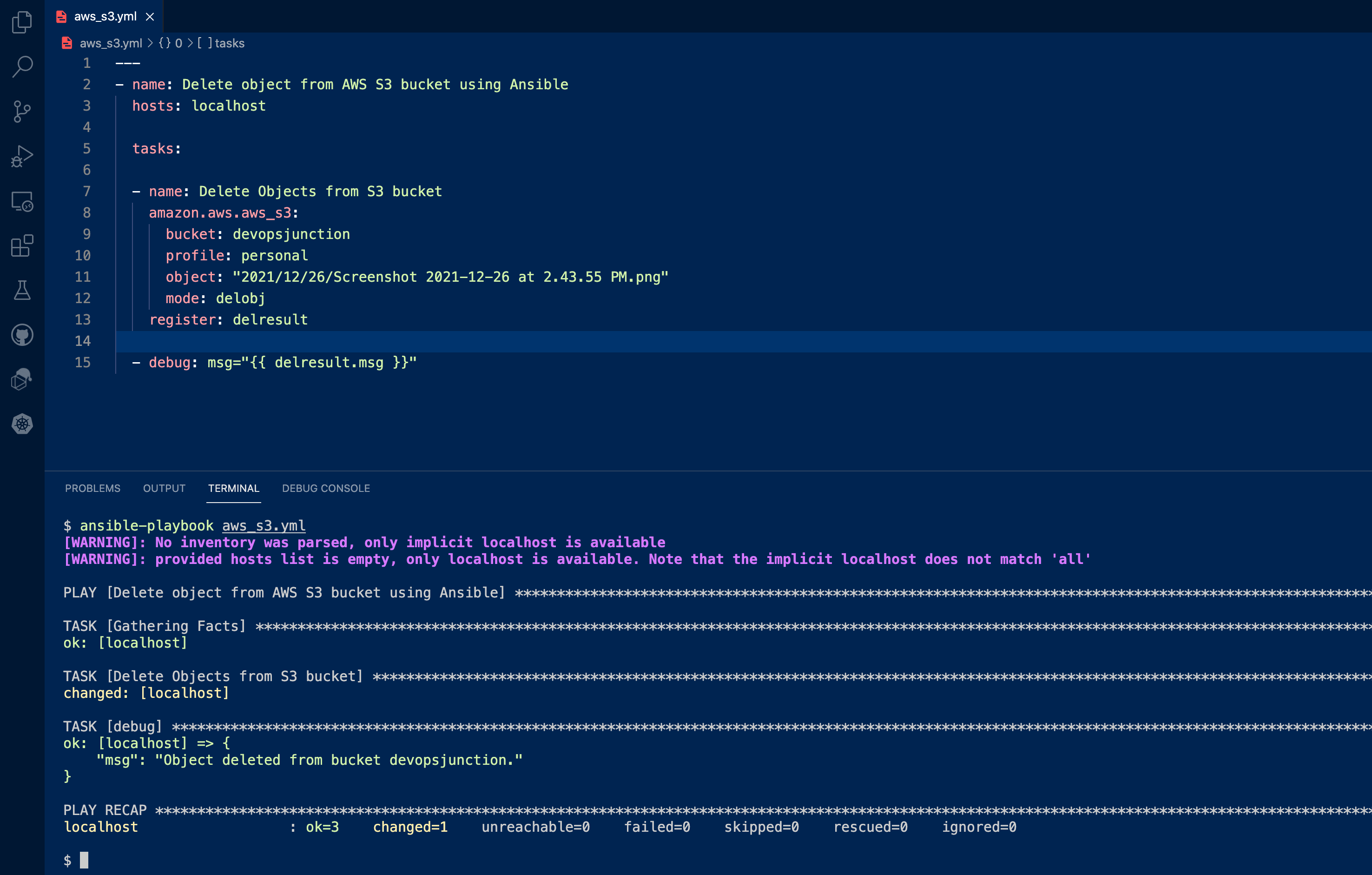
Ansible S3 Delete Objects example In this section, we are going to see how to Delete Objects from S3 using Ansible. to delete objects you need to use the mode: delobj in your task Here is the playbook to delete an object from the S3 bucket using ansible --- - name: Delete object from AWS S3 bucket using Ansible hosts: localhost tasks: - name: Delete Objects from S3 bucket amazon.aws.aws_s3: bucket: devopsjunction profile: personal object: "2021/12/26/Screenshot 2021-12-26 at 2.43.55 PM.png" mode: delobj register: delresult - debug: msg="{{ delresult.msg }}"Here is the execution output of this playbook
There are a few things I have noticed with Ansible S3 Delete, I thought you should be aware of this Quick caveats Ansible Delete Object does not check if the object is actually present or not.聽 Even if the object is not present it returns the Successful message Object deleted from bucket You Can delete the directories using delobj ansible s3 delete only when the directory is empty. otherwise, it would give a Successful message but not the deletion does not happen The successful message comes despite the deletion status of the file. Which seems buggy.So make sure to inspect twice if the object is really deleted in these cases. ( These caveats are made based on the observation made as of 29 Dec 2021. If its fixed we will try to keep this updated (or) please let us know in comments ) Ansible S3 Copy Objects example - Copying between S3 buckets In this section, we are going to see how to copy objects between two s3 buckets using ansible Here is the playbook that performs the transfer between two S3 buckets or copies objects from one bucket to another. Truth be told, we have not been able to test this Copy module successfully and this playbook was created as per the Ansible documentation. We have created an issue to Ansible https://github.com/ansible-collections/amazon.aws/issues/602 We will keep this article updated as soon we get more info on this one. --- - name: Copy objects from one S3 bucket to another bucket using Ansible hosts: localhost tasks: - name: Copy Objects from one S3 bucket to another amazon.aws.aws_s3: bucket: gritfy.io profile: personal object: sqscli-mac.zip mode: copy copy_src: bucket: devopsjunction object: sqscli-mac.zip register: copyresult - debug: msg="{{ delresult.msg }}"
Meanwhile, you can use the AWS CLI S3 CP command to perform this task. We have a dedicated article for the same AWS S3 CP Examples – How to Copy Files with S3 CLI | Devops Junction Conclusion In this detailed article, I have tried to cover as many as examples possible for the Ansible aws_s3 module usage How to list S3 objects using Ansible using prefix and max_keys etc Upload S3 Objects using Ansible with template and metadata Download S3 objects using Ansible recursively and based on checksum etc How to Delete the Objects from S3 using Ansible How to Copy objects between two S3 bucketsHope you found all the examples helpful. we have tested each playbook as always and we have mentioned if we have noticed any issue as a caveat. If you have any feedback or questions. please use the comments section.
Cheers Sarav AK 
Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel Signup for Exclusive "Subscriber-only" Content More from Middleware Inventory AWS S3 CP Examples - How to Copy Files with S3 CLI | Devops Junction
AWS S3 CP Examples - How to Copy Files with S3 CLI | Devops JunctionAWS CLI has become a life saver when you want to manage your AWS infrastructure efficiently. This also provides lot of possibilities for Automation and reduce the number of times that you have to login to AWS Management console. If you are new to AWS CLI. Please consider reading this…  Ansible Find multiple files with pattern and replace
Ansible Find multiple files with pattern and replaceIn this post we are going we are going to see how to find a list of聽 files containing a text or a pattern and replace them at once. As you know I have written a dedicated and brief articles on both Ansible find and replace modules with many examples.…  Ansible Inventory_hostname & ansible_hostname Examples
Ansible Inventory_hostname & ansible_hostname ExamplesIn this post, we are going to see two built-in variables of ansible mostly used in Ansible playbooks and they are inventory_hostname and ansible_hostname while both these variables are to give you the hostname of the machine. they differ in a way, where it comes from. So in this article,…  Ansible Playbook Examples - Sample Ansible Playbooks | Devops Junction
Ansible Playbook Examples - Sample Ansible Playbooks | Devops JunctionIn this post, we are going to see examples of Ansible playbook and various different modules and playbook examples with various modules and multiple hosts. We will start with a basic Ansible playbook and learn what is task and play and what is playbook etc. What is Ansible Playbook It…  Ansible Find Examples - How to use Ansible Find
Ansible Find Examples - How to use Ansible FindAnsible find module functions as same as the Linux Find command and helps to find files and directories based on various search criteria such as age of the file, accessed date, modified date,聽 regex search pattern etcetera. As said earlier, this is more of an ansible way to execute the… |

【本文地址】